The first time I’ve heard about dbatools was on its early stages and, although it seemed really interesting, I didn’t know anything about PowerShell, nor I had to work with SQL professionally. Moreover, to me it looked like it was “focused” on helping DBAs (maybe hence its name?). Even though I’ve never contributed to the project, I’ve always kept an eye on it.
Why do I need it now? Some context 🔗
I usually have to analyse logs in order to perform some C#/SQL troubleshooting/debugging/performance tuning. The approach that I usually take is to use Excel and import the log file as a table, so that I can filter, highlight and so on.
For most of the times, this is enough and I can get my job done. But there were times that I’ve struggled when trying to filter for more than one condition on same column, some issues with sorting, wrong data types, etc.
But there’s more 🔗
I’ve decided that I want to learn more about Linux and because (for me) the best way to learn something is by use and investigating, I’ve installed Ubuntu to be my daily driver.
Fortunately, one can now easily use SQL Server on Linux, as well as .NET and PowerShell. I’ve been using a docker container with SQL Server, and for that reason the installation and database restore were really easy and fast to get working (hint: I will probably write a dbatools isn’t just for DBAs part 2 - Backup and Restore).
After setting everything, I had to analyse a log and, to my surprise, I couldn’t find that Excel feature that I was used to in LibreOffice . I’ve decided to try OpenOffice, but the result was the same.
Ok so what now? - The solution 🔗
I’ve once explored a way to store logs on a database.
And after some digging and talking to Cláudio Silva (b|t), he suggested that I took a look at a dbatools’ cmdlet: Import-DbaCsv.
Because I’m more comfortable with SQL than with Excel, this seems a good case to use what I’ve learned at that time.
I can even has some advantages, such as:
- You can easily do a multi condition filtering: i.e. All logging info that contains the string “Entered on controller” OR “Left the controller”. In excel, I only know how to filter by one condition (I’m sure there might be some way to achieve this);
- It’s easier to keep track of filters: Because in SQL it will all be in a WHERE clause, one can easily look at that and understand what’s being filtered. In Excel you have to look at the headers, find the filter symbol, and click on it to see the filter condition.
- If you have the info, you can join with other tables to gather even more information: Ok, this only works if you are analysing logs from development (I’m assuming you don’t have the production data on your development environment). Let’s say that you are storing the id of the user that made the request. You can do an Inner Join with the user table, and get more information about that user.
- It’s easier to show/hide columns: In Excel it feels I’m playing a puzzle game whenever I want to hide/show columns or sort it in different order. In SQL all I have to do is change the SELECT statement.
- Faster loading data - When I want to analyse a new log file, all I have to do is call a PowerShell function (we’ll see it later) that gets the path as parameter, imports everything to the database and it’s good to go. In Excel I have to go to the data tab, choose import and select the file. As bonus, excel always converts my
Datecolumn and removes the seconds and milliseconds, which are relevant when analysing performance.
For all of these, I’ve decided to drop Excel/LibreOffice and go with SQL.
Implementation 🔗
I suggest you take a look at Import-Csv documentation, as it contains many parameters that can make sense for your case.
Let me show you the final execution, and we will break it down to understand what it’s doing:
Import-DbaCsv -Path '/media/daniel/Data/logs/logExample.log' -Delimiter '|' -SqlInstance "Localhost" -SqlCredential $credentials -Database 'LogHolder' -AutoCreateTable
Path: As the name implies, this is the path for the log file. Notice that it accepts anObject[], meaning you can pass multiple files to be processed;Delimiter: As you might or might not know, although it’s called csv (Comma Separated Value), the delimiter can be other character. For example in my case it is the pipe ->|;SqlInstance: The instance you will target to write the content;SqlCredential: APSCredentialobject which holds the credentials to get access to the instance;Database: The target database on which the content will be written.AutoCreateTable: Here’s something really cool about this one - Let’s say that you don’t care about the attributes type (whether it’s anvarchar, adatatimeoffset, etc), or you don’t want to create the table manually because your csv contains 30 columns and you just want a quick way to dump and analyse the information. You can use the-AutoCreateTableswitch, which, as the name implies, will create the table for you, with the columns you have on your csv. If you don’t specify aTablename, it will create the table with the name of your csv fileTable: The target table to which the content will be written. Although it’s not present here, it will be used later.
Let’s look at some examples 🔗
For this case, we will use a log that I’ve generated. It has some columns that are usually useful for a dotnet api log. Note that this is some random non-sense generated data.
For this first iteration, we will use the -AutoCreateTable and see how it behaves.
Let’s run the command I’ve shown above:
$paramSplat = @{
Path = '/media/daniel/Data/logs/logExample.log'
Delimiter = '|'
SqlInstance = 'Localhost'
SqlCredential = $credentials
Database = 'LogHolder'
AutoCreateTable = $true
}
Import-DbaCsv @paramSplat
Well, that’s the same command but formatted differently. I’ve used splatting because I consider that it makes the core more readable and easier to change any parameter, if we have to.
Here’s the result of that execution:
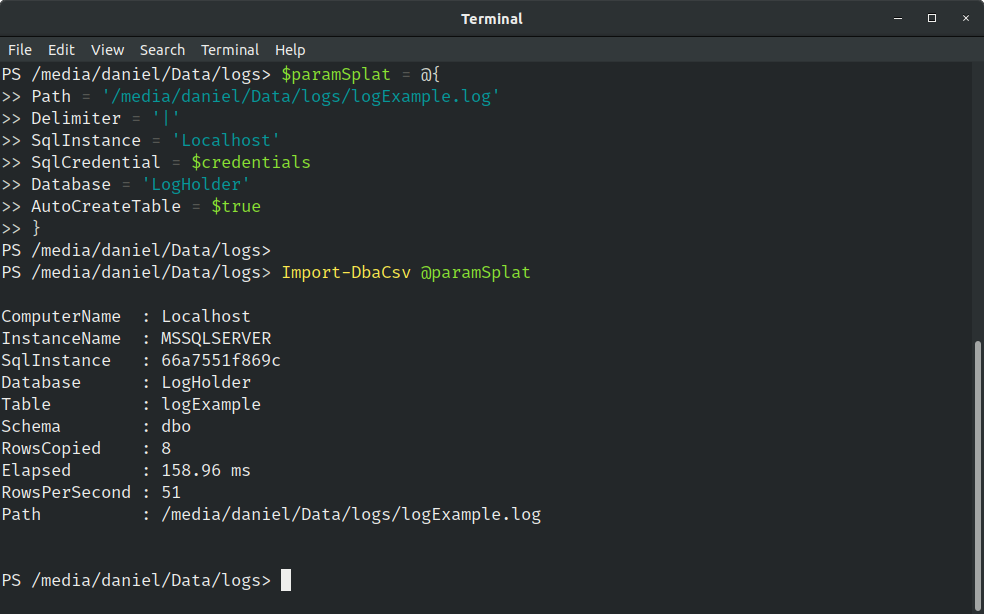
Interesting/Relevant points:
- Notice the
Tablename on the output. As I’ve said, the table name has the same name as the log file because we haven’t specified a table name. - It gives us the information of how many rows were copied, plus at which “rate” it wrote (notice the 51 RowsPerSecond)
Let’s take a look at our table, shall we?
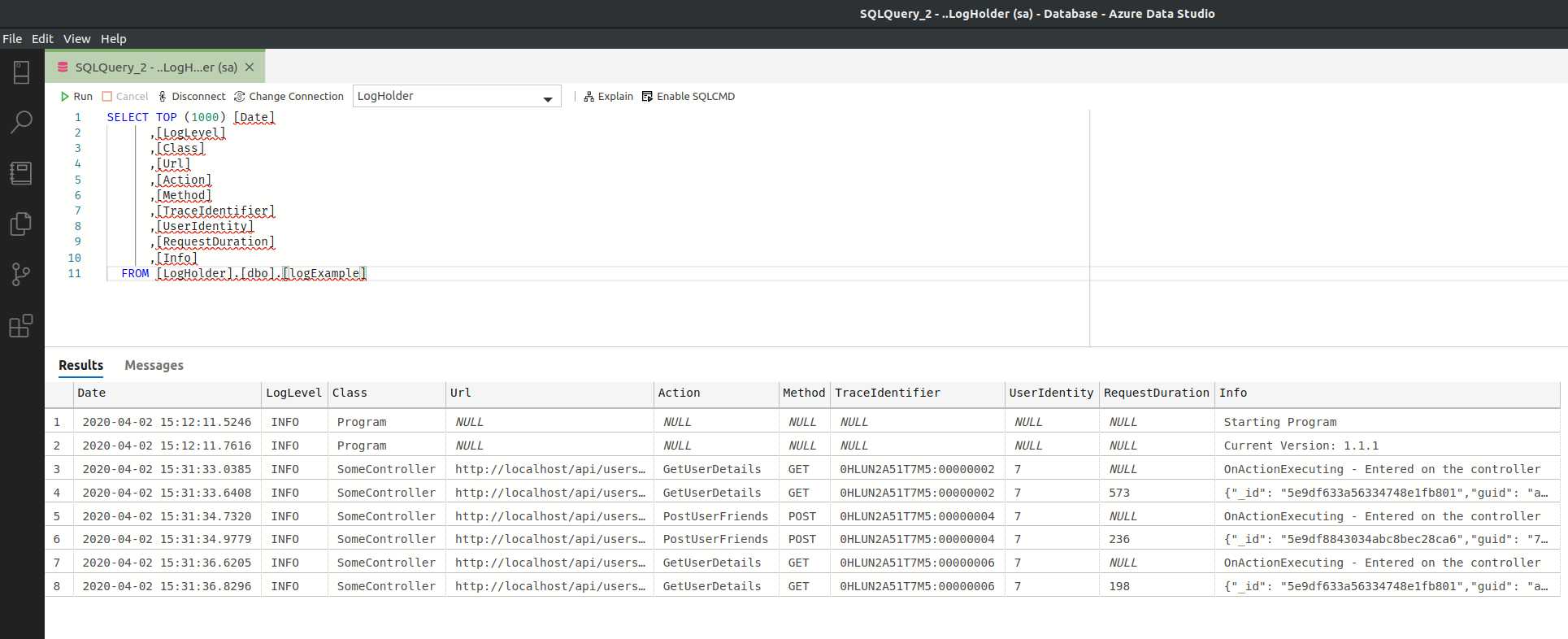
Well, that’s pretty much what was expected at this point. And that’s good! From now on, we are querying SQL which, for my case and with my experience, is much more powerful in this scenario.
What about bigger files? 🔗
Before we proceed, I think it makes sense to list the specs of my machine, so that we can take better conclusions when considering times.
It is an 8th gen i5 (i5-8265U Quad-Core, 1.60 GHz with Turbo up to 3.90 GHz, if it matters), 16GB of RAM.
Let’s try to create a bigger file and then import it on our existing table. And let’s use PowerShell to do just that:
$originalFilePath = '/media/daniel/Data/logs/logExample.log'
$copyFilePath = '/media/daniel/Data/logs/logExampleMultiplied.log'
Copy-Item -Path $originalFilePath -Destination $copyFilePath
Out-File $copyFilePath -Append -InputObject " " #force a new line, so that when we append the info, it will be appended to the beginning of a new line
1..5000 | foreach-object { Get-Content $originalFilePath | Select-Object -Skip 1 } | Out-File $copyFilePath -Append
#Select-Object -Skip 1 allows us to copy everything other than the header
So, our original sample has 8 lines, now we’ve multiplied that by 5000, which means we will add 40000. In total, we will add 40008 new records. Let’s see how it behaves now.
$paramSplat = @{
Path = '/media/daniel/Data/logs/logExampleMultiplied.log'
Delimiter = '|'
SqlInstance = 'Localhost'
SqlCredential = $credentials
Database = 'LogHolder'
Table = 'logExample'
}
Import-DbaCsv @paramSplat
Notice that I’ve now removed the AutoCreateTable switch and specified the table name instead. This is because I want to append the new results to our existing table.
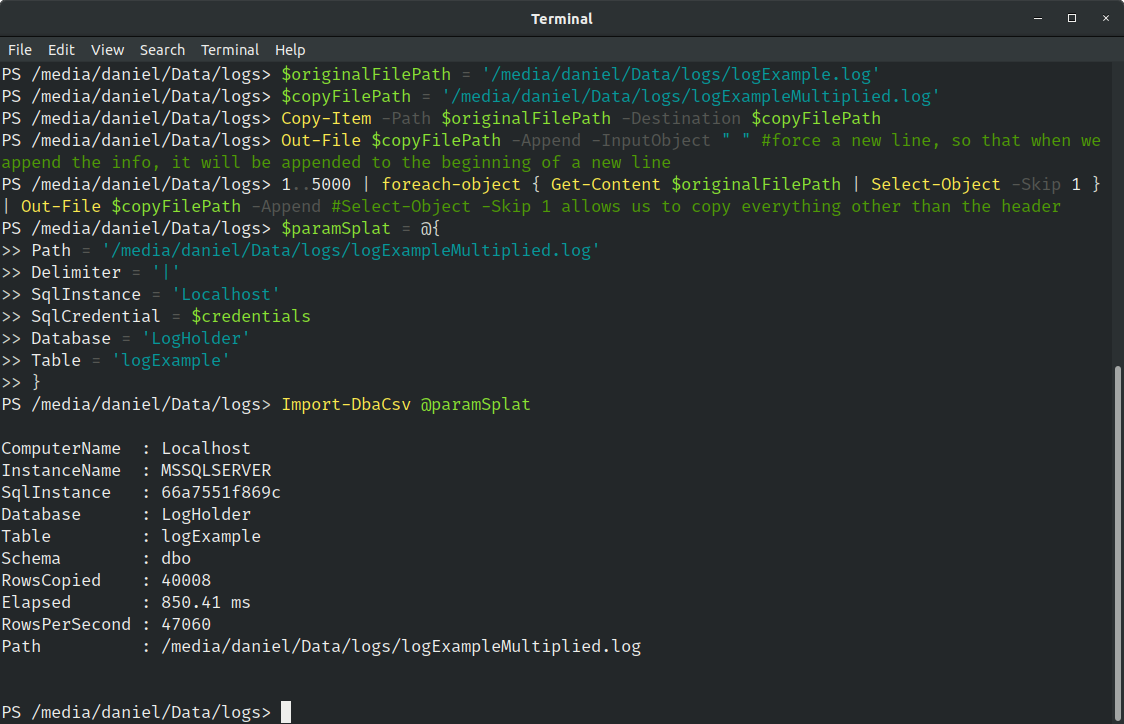
Our multiplication generated a file with 8.7MB. Well that’s not that big… But it was processed at a rate of 47060 rows per second, still taking less than 1 second 🤯.
Ok I should not be surprised by that. Compared to what SQL can handle, 40k rows is nothing…
For that reason, I’ve grabbed the created file and multiplied that for 500. So now we have 500x40.008 rows, which makes a total of 2.000.400 rows.
Now that gotta be something! PowerShell even took some time to create that file.
How long do you think that it will take (on my machine) to import 2 million records?
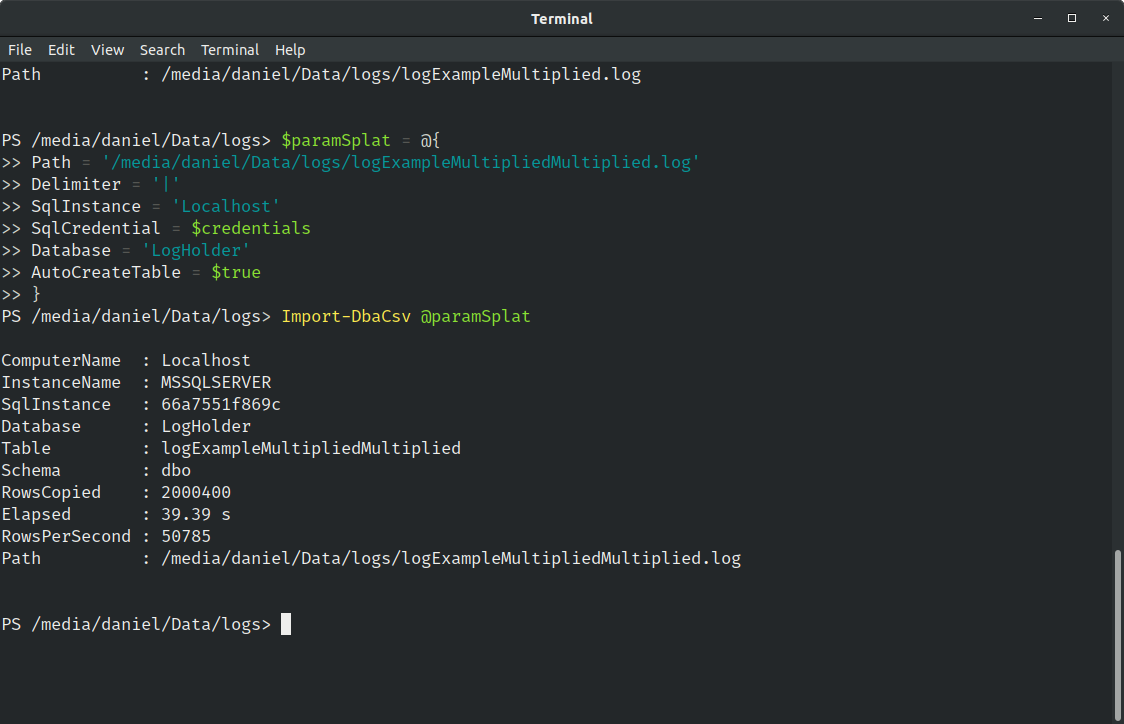
39.39 seconds to copy 2.000.400 rows, at a rate of 50785 rows per second. Still pretty amazing if you ask me!
There’s also a -BatchSize parameter that you can explore and try to improve the time even more.
Querying our Logs 🔗
From here, is really up to you to apply whatever filters, joins, etc that you want.
For instance, say that we want to get all results between a certain time, and only care about the date and info column. In Excel any of the other mentioned programs, we need to select the columns and then select “hide”. After, we need to understand how to filter ranges. Here’s a dedicated office support page, and here’s a page explaining some filters in LibreOffice.
Just look at the amount of steps you need to take just to filter the columns.
The same search in SQL would be like this:
SELECT [Date], [Info]
FROM [logExample]
WHERE [date] BETWEEN '2020-04-02 15:31:34.7320' AND '2020-04-02 15:31:36.6205'
Adding filter clauses is easy. Say that from such dates, you only want the rows that have requestDuration.
SELECT [Date], [Info]
FROM [logExample]
WHERE [date] BETWEEN '2020-04-02 15:31:34.7320' AND '2020-04-02 15:31:36.6205'
AND [RequestDuration] IS NOT NULL
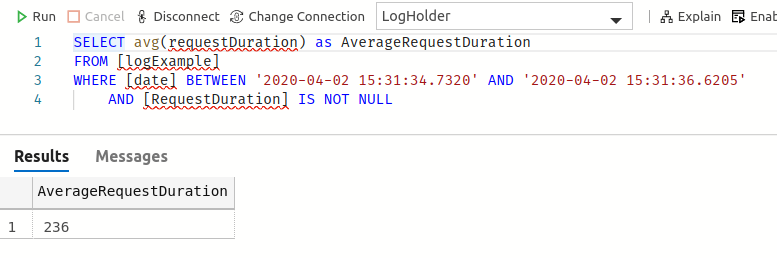
Or because you know that the RequestDuration is the total time spent on the API for a given request, you want to know the average request duration for GET requests between two dates:
SELECT avg(requestDuration)
FROM [logExample]
WHERE [date] BETWEEN '2020-04-02 15:31:34.7320' AND '2020-04-02 15:31:36.6205'
AND [RequestDuration] IS NOT NULL
Started executing query at Line 1
Msg 8117, Level 16, State 1, Line 1
Operand data type varchar(max) is invalid for avg operator.
Total execution time: 00:00:00.001
Ups… What’s wrong?
About the defaults 🔗
The error above states that the type varchar(max) is invalid for avg operator.
Let’s script the table as a create to see what we have.
Remember, this table was created by dbatools due to the AutoCreateTable switch:
CREATE TABLE [dbo].[logExample](
[Date] [varchar](max) NULL,
[LogLevel] [varchar](max) NULL,
[Class] [varchar](max) NULL,
[Url] [varchar](max) NULL,
[Action] [varchar](max) NULL,
[Method] [varchar](max) NULL,
[TraceIdentifier] [varchar](max) NULL,
[UserIdentity] [varchar](max) NULL,
[RequestDuration] [varchar](max) NULL,
[Info] [varchar](max) NULL
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
Ah… everything is varchar(max). If you are using this just for quick, simple queries that don’t require and specific data type, you can skip this part.
In our case, we will have to at least change the RequestDuration column to be a BIGINT.
I will also change the userIdentity and you will understand why in a second.
If you want to use this table in long term, I suggest you tune it, by setting the correct data types, indexes and so on.
ALTER TABLE logExample
ALTER COLUMN RequestDuration BIGINT
ALTER TABLE logExample
ALTER COLUMN UserIdentity BIGINT
By running this and rerunning the query, we will get the expected result
Final example - Or a challenge if you will 🔗
In order to try to make a point again about why I like this SQL > Excel solution so much, let’s consider this request
I need to know the name of the user that made the request to the “GetUserDetails” for the user with id 3. More than that, I need to know how many friends does this user 3 has. All I know is that the request was made between 15:31:34 and 15:31:37
This seems to be a rather specific request, but hopefully you understand the power that you have while querying the database vs Excel/LibreOffice/OpenOffice.
Let’s brake this into parts (and make assumptions for this log file):
- Name of the user that made the request - The
UserIdentitycolumn has the id of the user that made the request on the database. The name is stored in the database - GetUserDetails - It is our
Actioncolumn - User with id 3 - This is present in the URL on the request - 3 is the id of the user
- How many friends this user 3 has: The return of the GetUserDetails return a JSON that contains a list of friends
The Excel/LibreOffice/OpenOffice approach 🔗
- Filter the
Datecolumn with a range. - Filter the
Actioncolumn to contain only the “GetUserDetails” - Filter the
URLcolumn to contain only entries for that specific URL (in this casehttp://localhost/api/users/3/) - Check the UserIdentity column and go to database and search for that Id
- OPTIONAL: We can filter by RequestDuration being not null because when there’s a request duration, it’s the response.
- Copy the info column to a text editor, format it as JSON and count the number of friends.
The SQL approach 🔗
We can pretty much apply the filters above, but there are 2 main advantages.
We can perform an INNER JOIN with the user table, and we can convert the Info column, which we know it’s a JSON , to a table and count the friends.
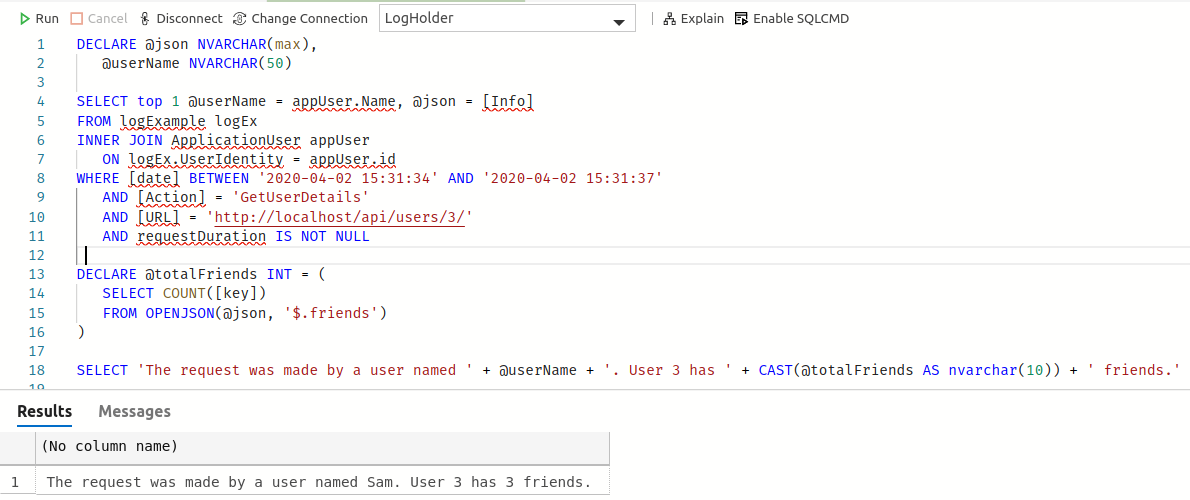
Here’s such code:
DECLARE @json NVARCHAR(max),
@userName NVARCHAR(50)
SELECT top 1 @userName = appUser.Name, @json = [Info]
FROM logExample logEx
INNER JOIN ApplicationUser appUser
ON logEx.UserIdentity = appUser.id
WHERE [date] BETWEEN '2020-04-02 15:31:34' AND '2020-04-02 15:31:37'
AND [Action] = 'GetUserDetails'
AND [URL] = 'http://localhost/api/users/3/'
AND requestDuration IS NOT NULL
DECLARE @totalFriends INT = (
SELECT COUNT([key])
FROM OPENJSON(@json, '$.friends')
)
SELECT 'The request was made by a user named ' + @userName + '. User 3 has ' + CAST(@totalFriends AS nvarchar(10)) + ' friends.'
Although the SQL code seems more verbose, I still consider it to be better, because you can save the query and re-use it whenever necessary, only having to adjust some parameters.
Conclusion 🔗
This blog post became longer than I anticipated, but the main idea here is not to discuss Excel/LibreOffice/OpenOffice vs SQL.
3 main points to be highlighted:
- Even if you are not a DBA, you can leverage from dbatools
- If you are not on Windows, or don’t feel familiar with the named tools to analyse logs, SQL can be an option (if you read until this point, I assume you are comfortable with SQL).
- Import-DbaCsv combined with SQL Querying can scale pretty easily and (probably) even save you tons of time if you are always looking at the same points.
Hope that you find this useful, and thanks for reading!